Your AI ships code faster than anyone can review it. BreachLens finds the vulnerabilities it introduces — and proves which are exploitable.
AI assistants write more of your code every day, and the flaws ship with it. BreachLens scans that code — plus your containers, cloud, and running apps — then runs controlled exploitation to confirm what an attacker could actually reach. Every confirmed finding ships with a reproducible command that replays the attack. It runs on your infrastructure, with your own AI model — the proof never leaves your network.
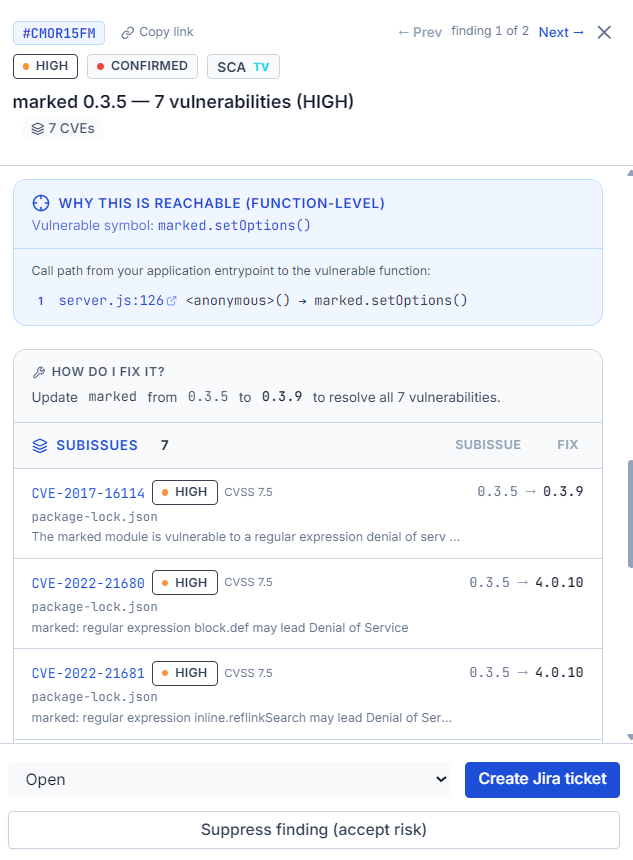
A finding you can't reproduce is a guess.
Every other scanner ends at a ranked list. BreachLens takes each candidate finding and attempts the exploit under authorization — in an isolated browser, recorded. Only findings it can actually reproduce earn the CONFIRMED badge. So your team debates the fix, not whether the bug is real. Here's the entire mechanism, start to finish:
A scanner flags a candidate
A scanner surfaces a possible issue in code, a container, cloud config, or a running app.
Controlled exploitation
BreachLens tries to exploit it against your authorized target, in an isolated browser — and records what happens.
Evidence attached
If it works, the finding ships with a reproducible curl, the evidence URL, and a replay you can watch.
One self-hosted platform. The whole scanner stack.
Consolidate the point tools instead of stitching them together — code, cloud, and runtime in one engine, one data model, one place your team works.
Find
Every major scanner class, in one deployment.
- SASTStatic analysis for injection & insecure patterns
- SCAVulnerable & outdated dependencies
- SECRHardcoded credentials, keys & tokens
- IaCTerraform / K8s / cloud misconfig
- CTNRImage OS & dependency CVEs
- DASTDynamic testing of running apps & APIs
- PENTAuthorized, controlled exploitation
- CLDCSPM for AWS · Azure · GCP · GitHub
- AIRed-team for LLM apps, agents & MCP
Prove
Evidence, not just alerts — the unhostageable differentiator.
- · Proof of exploit — a reproducible command that replays the attack end to end.
- · Recorded replay — capture an authenticated journey and drive testing through the flows that matter.
- · Kills false positives — proves it to your team, and to auditors, with evidence instead of a CVSS score.
Prioritize
Cross-tier attack paths, scored by real reach.
- · Attack paths — links code, container, cloud & pentest findings into one chain across an application.
- · AI verdict per chain — a narrative plus a likely-real / mixed-signal / likely-noise judgment.
- · Function-level reachability — is the vulnerable dependency actually called? Across major language ecosystems.
Fix
Turn findings into reviewed pull requests.
- · AI auto-fix — drafts the patch and opens a PR/MR for your team to review.
- · Bring your own model — Anthropic, OpenAI, Gemini, or fully local Ollama.
- · Nothing auto-merges — a human is always in the approval seat; no code leaves your environment.
Report & govern
Audit-ready output procurement asks for.
- · Compliance reports — auto-mapped to OWASP Top 10, API, LLM & CI/CD.
- · SBOM + signing — CycloneDX / SPDX with cosign-compatible signatures.
- · Preventive → corrective — shift-left gates, the scanner set, and the fix loop in one place.
Runtime & posture
Coverage past build time, into newer attack surfaces.
- · Kubernetes posture — CIS-style cluster & RBAC assessment.
- · Runtime sensors — bundled eBPF host & workload detection.
- · MCP & LLM red-team — probe agents & models for prompt injection and exfiltration.
Five tiers, one attack path, one verdict.
A SAST bug, a vulnerable dependency, an exposed container, a proven exploit, and a runtime signal aren't five tickets — they're one attack path. BreachLens links them across an application boundary and lets AI judge whether it's real.
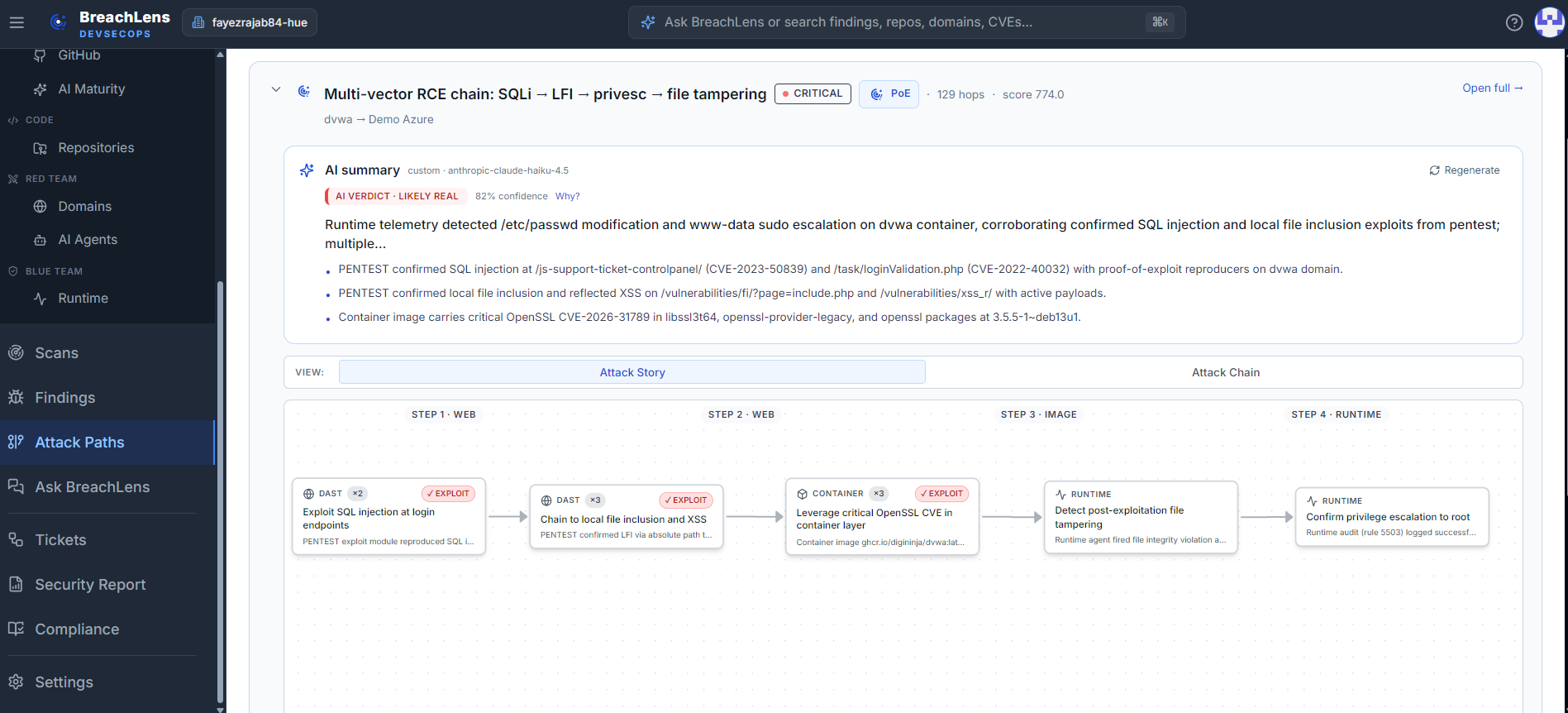
Runs on your infrastructure. Nothing leaves it.
All that proof — the findings, the attack paths, the exploit evidence — is generated where your systems live and stays there. No SaaS tenant, no third party in your trust boundary: the one thing a cloud-hosted pentest agent structurally can't offer.
- Self-hosted is the default path, not an upsell. A single Docker Compose stack on your own cluster — the same install everyone gets.
- Fully air-gapped. Zero outbound dependencies in offline mode — including the AI, via local Ollama inference.
- No third party in your trust boundary. No external account to be approved for, no prompts or findings sent to anyone else's cloud — bring your own model or run it fully local. The exploit evidence stays under your control.
- Fits your pipeline. GitHub & GitLab CI templates, a standalone CLI, webhooks, and a documented API — least-privilege scopes, disclosed.
Don't take our word for it. See the proof.
Other vendors open with a wall of Fortune-500 logos. We can't — we're new. So instead of borrowed trust we hand you the earned kind: open docs, a real sample report, and a live run against a deliberately-vulnerable target. Verify it yourself before you ever talk to us.
Live walkthrough
We run BreachLens against a deliberately-vulnerable target and walk you through the findings, attack paths, and a proof-of-exploit replay — live.
book a demoDocs & API reference
The real install guide, CLI, and interactive API playground — versioned, with a changelog. No form to read it.
docs.breachlens.appSample report
A sanitized compliance + proof-of-exploit report — the exact artifact your auditors and procurement will see.
request a copyThe questions a security team actually asks.
Does our code or data ever leave our network?
Is it really self-hostable, or is that a SaaS checkbox?
Is the "proof of exploit" real, or a dressed-up severity score?
CONFIRMED when BreachLens actually reproduced the exploit against your authorized target. The evidence includes a runnable curl command and the evidence URL — you can run it yourself against a lab target and watch it work. It is not a heuristic confidence number.How does it fit our pipeline and tools?
@breachlens/cli for any runner, webhooks, and a documented REST API. Auto-fix opens PRs/MRs in your SCM; reports export to the formats procurement expects. Integration scopes are least-privilege and disclosed in the docs.